Fetch as Googleでページがどのようにレンダリングされているかを確認
公開しているWebページをGoogleのクローラーがどのように見ているのかについてFetch as Googleを使用することで確認することができます。画像などのリソースやCSSなどが適切に読み込まれているかどうかを確認する場合に便利です。ここではFetch as Googleでどのようにレンダリングされているのかを確認する方法について解説します。
1.ページを取得してレンダリング
2.取得できないリソースがあった場合の例
3.スマートフォン向けのクローラーでレンダリング
では実際に試してみます。Search Consoleにログインし、対象のサイトのダッシュボードを表示して下さい。
画面左側の「クロール」メニューの中にある「Fetch as Google」メニューをクリックして下さい。
「Fetch as Google」画面が表示されます。
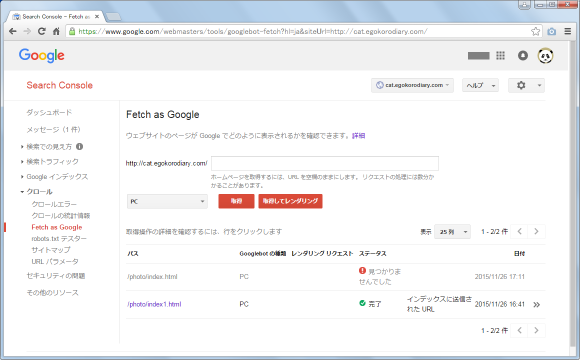
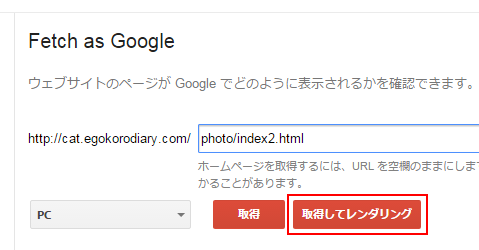
テキストボックスにレンダリングを行いたいページへのパスを入力して下さい。対象のページがホームページであれば空白のままで構いません。
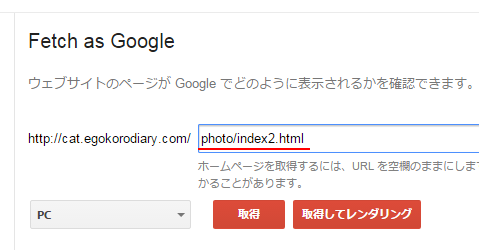
パスを入力したら「取得してレンダリング」をクリックして下さい。
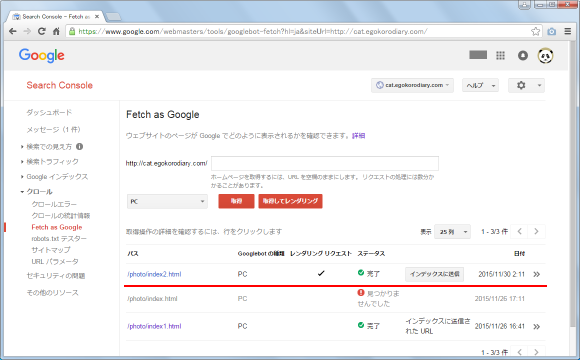
先ほど入力したパスのページに対して、(デフォルトではPC向けの)クローラーがクロールしてページの内容を取得します。取得できるまではステータスが「保留」となっていますが、次のように「完了」と表示されていれば無事取得が完了しています。「取得してレンダリング」を行った場合は「レンダリング リクエスト」の項目にチェックが入っています。
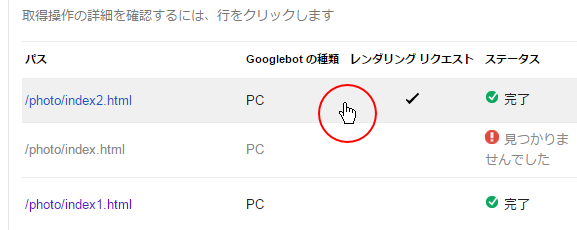
どのようにレンダリングされたのかを確認するには、対象の行をクリックして下さい。
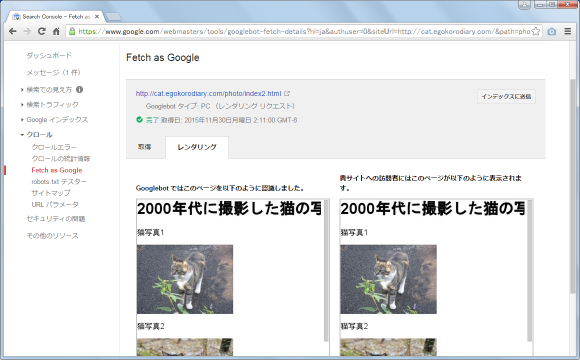
対象のページが人がブラウザから見た場合にどのように表示されるのか(右)とクローラーが取得したページをレンダリングした場合にどのように表示されるのか(左)の両方が表示されます。
ページを構成する画像やCSSやJavaScriptなどにGooglebotがアクセス出来ない場合、左側の画像は大きく崩れて表示される場合があります。もし意図した通りにレンダリングが行われていない場合、次のリソースの取得に失敗した場合を参照してみて下さい。
例としてこのページで表示している画像ファイルをクローラーにだけアクセスできないようにrobots.txtに記載してみます。その後で改めて同じページを「取得してレンダリング」してみると今度は次のように表示されました。
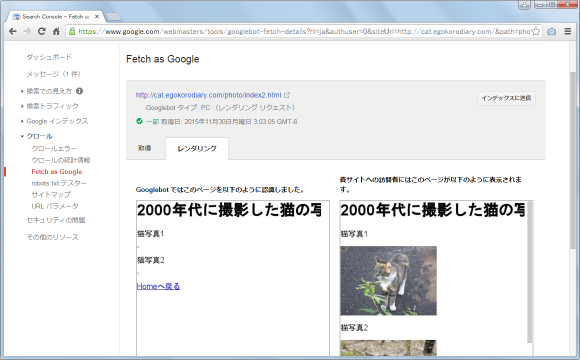
ブラウザ経由で見てる場合には画像が表示されますが、クローラーは画像にアクセスできないためレンダリングした時に画像が表示されません。また画面下部にはクローラーが取得できなかったリソースの一覧が表示されます。
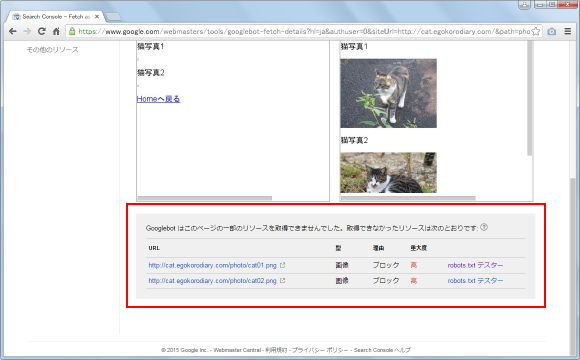
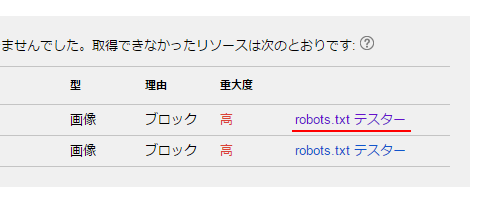
「理由」や「重大度」などが表示されます。robots.txtでブロックされている場合は行の右側に表示されている「robots.txt テスター」と書かれたリンクをクリックして下さい。
Search Consoleの「robots.txt」のテスト機能で、robots.txtのどの部分でブロックされているのかを確認することができます。(詳しくは「robots.txtの構文チェックと動作確認」を参照して下さい)。
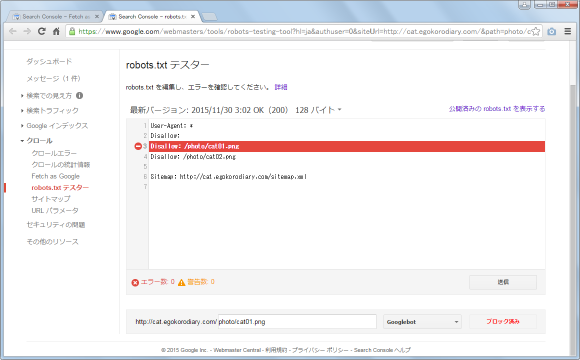
クローラーが全てのリソースを取得できる必要はありませんが、重要と思われるリソースの取得に失敗した場合などは「理由」などを参照して見て下さい。
デフォルトではPC向けのクローラーを使ってページの取得とレンダリングを行ってきましたが、スマートフォン向けのクローラーを使った場合にどのように取得とレンダリングが行われるのかを確認することができます。
Fetch as Googleの画面で「PC」と表示されている個所をクリックして下さい。
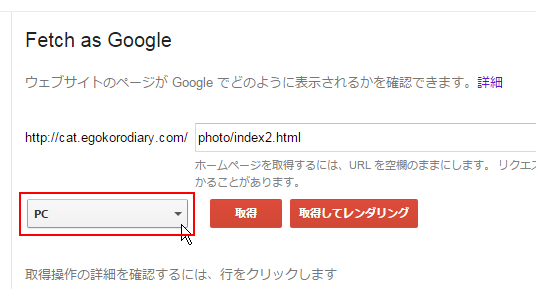
クローラーの種類を選択できます。PC向けは「PC」、スマートフォン向けは「モバイル:スマートフォン」、ガラケー向けは「モバイル:XHTML/XML」か「モバイル:cHTML」のいずれかを選択して下さい。(なおガラケー向けのを選んだ場合はレンダリングは行えません)。今回はスマートフォン向けを選択しました。
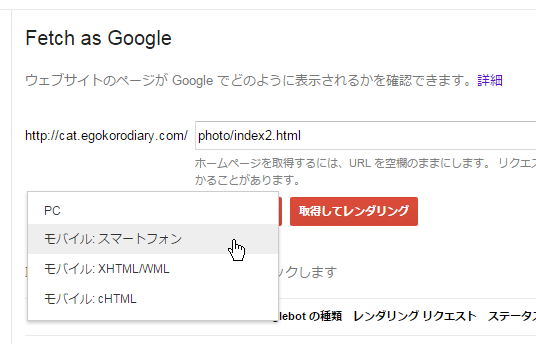
「取得してレンダリング」をクリックして下さい。
取得が完了しましたら対象の行をクリックして下さい。
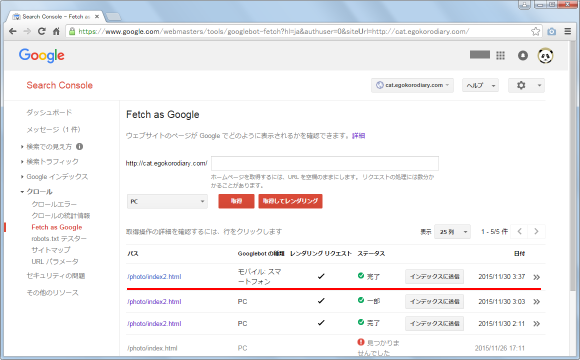
スマートフォン環境で対象のページを見た場合と、スマートフォン向けのクローラーが取得したページをレンダリングした場合にどのように表示されるのかの両方が表示されます。
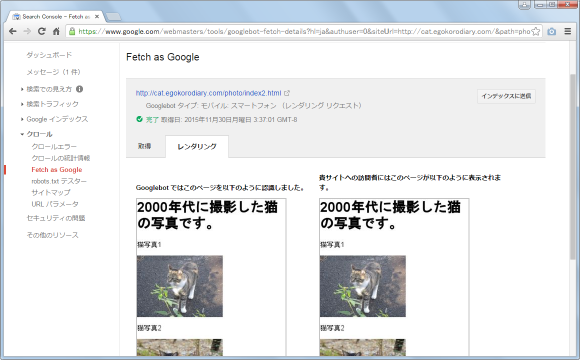
PCの場合と同じようにクローラーに対して重要なリソースなどが取得できているかどうか、スマートファンの環境でも意図した通りに表示されているかどうかを確認されてみて下さい。
( Written by Tatsuo Ikura )

